
If you operate a website, or you scrape data from the web, you may be curious about your legal rights. Web scraping raises issues with copyright, data privacy and user agreements.
Here's what you need to know about whether web scraping is legal or not, and how to navigate that aspect of data collection.
- 1. What is Web Scraping?
- 2. Are There Laws Against Web Scraping?
- 3. Does Web Scraping Breach Copyright?
- 3.1. Is the Information Copyrightable?
- 3.2. Does Fair Use Apply?
- 3.3. Does the Digital Millennium Copyright Act (DMCA) Apply?
- 4. Does Web Scraping Breach Data Protection Laws?
- 5. How Can I Stop Web Scraping?
- 6. Summary
What is Web Scraping?
Web scraping is a practice of gathering data from web pages. It is usually done with specialist, automated software. Web scraping usually has two characteristics:
- It's automated, collecting far more data, more accurately in less time than a human could do.
- It extracts specific information rather than simply copying an entire page.
An easy example to understand of web scraping is a price comparison site. A simple example would be using software to visit multiple online booksellers, find the price they charged for a particular book, then compile them into a list to find the cheapest.
A more complex example would be checking multiple airlines to find prices and options for a particular route. This would often involve running a specific query at each airline site.
Are There Laws Against Web Scraping?

No laws specifically ban web scraping. Some websites and lawyers have argued that web scraping violates the U.S. Computer and Fraud Misuse Act, but this has not been established through court rulings.
Web scraping could fall under the jurisdiction of laws indirectly. This could happen even when gathering the data through web scraping doesn't break the law. The reasons for doing so, or the way somebody uses the data after scraping it, may be illegal. Let's explore the possible reasons why.
Does Web Scraping Breach Copyright?

Web page content falls under the scope of copyright protection in many countries, so web scraping could be a copyright issue. It usually comes down to three questions:
- Is the information copyrightable?
- Does Fair Use apply?
- Does the Digital Millennium Copyright Act apply?
Let's look deeper at each of these.
Is the Information Copyrightable?
Generally, copyright only applies to creative work rather than facts. In the book price example, the book itself or a website's description or review of it would come under copyright. The fact a particular seller charges $15 for it would not.
However, compiling data into a particular list or a database could come under copyright. For example, simply scraping another website's list of the hundred best books of the year would likely violate copyright. Similarly, you couldn't just copy a book retailer's database of books and use it on your own site.
Does Fair Use Apply?
Most jurisdictions, including the U.S., have a fair use exemption to copyright laws. They usually allow you to use an extract of copyrighted material without permission for specific purposes such as literary criticism, news reporting or education. It also matters whether your use of the copyrighted material could affect the value it has to the copyright holder.
Does the Digital Millennium Copyright Act (DMCA) Apply?
The Digital Millennium Copyright Act (DMCA) says you can't circumvent measures designed to protect copyright.
This shouldn't affect web scrapers that simply replicate a human visiting a website and cutting and pasting information.
It could bar tactics such as finding a way around login pages, CAPTCHas or other methods designed to stop web scrapers and similar tools from accessing multiple web pages in a short period.
Does Web Scraping Breach Data Protection Laws?

Web scraping could breach data protection laws, either in the scraping itself or the way you use the data.
In this case, the issue is not with the website itself but rather the data subject: the person data is about.
Data protection laws usually deal with personal information, meaning any information about an identified (or identifiable) individual. This could be anything from a date of birth to an address, to details of web browsing activity, to health records.
Data protection laws such as the General Data Protection Regulation (GDPR) generally say you can only collect or use personal information in specific scenarios. The most common is that you have consent from the data subject, which is effectively impossible when you are scraping their details from a website.
Another scenario is that the data collection or use serves your legitimate interests. That means that it's part of your business activity and this doesn't outweigh the data subject's privacy rights. There's no guarantee you could rely on legitimate interests to cover web scraping.
Note that the GDPR covers "processing" personal information, and this includes simply collecting it, for example through web scraping. Note also that although GDPR has exemptions for some official public documents, the rules generally apply even to information that is publicly available, for example on a website.
Similar laws apply in several other countries, while several U.S. states have laws that restrict personal information collection in some way, for example buying and selling data. These all make it less likely that web scraping of personal information is lawful.
How Can I Stop Web Scraping?

If web scraping from your site isn't covered by copyright or data protection laws, you'll need to rely on the Terms of Use/Terms and Conditions of your website. In this case, you can make it a mandatory condition of being allowed to access your website that users do not engage in web scraping. This could involve stopping them accessing particular parts of your site or stopping them using the site at all.
In principle, imposing such a condition is straightforward as you just have to state "no web scraping" in your Terms agreement.
Here's how Co-op Levy Share explicitly bans web scraping:

FDA Tracker addresses web scraping in an Acceptable Use clause within its Terms of Service:
![]()
The problem is that you may have to prove the user saw and agreed to your Terms. To be certain of this, you can't rely on the "browsewrap" approach where you put the terms on your site and simply say that using the site counts as agreeing to them. Instead, you'll need to use a "clickwrap" approach where users see a banner or screen with the Terms (or a link to the document) and must actively signal agreement before they can access the site.
This can feel excessive when you apply it to the entire site, and it could deter potential visitors. It may be easier to restrict the ban on web scraping to parts of your site that have restricted access, for example requiring a free user account or a paid subscription.
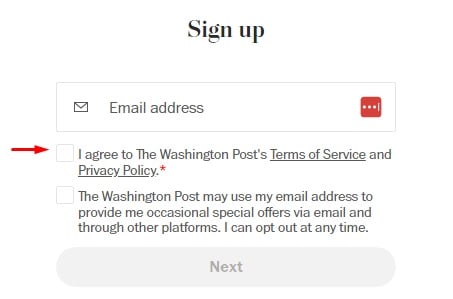
In this case you can show the Terms agreement (including the ban on web scraping) when somebody signs up. Use a checkbox (not pre-ticked) that's clearly marked as agreeing to the Terms, and make it impossible to proceed with a sign-up or account creation without ticking the box.
The Washington Post requires users to agree to its Terms of Service before they can sign up for an account:
Summary
Web scraping means using automated software to gather data from a website, often extracting and compiling specific information.
Web scraping is not illegal in itself. In certain circumstances it can breach copyright or data protection laws.
The most reliable way to deter web scraping is to ban it as part of your website's Terms agreement. To be sure this will have legal standing, you'll have to prove users agreed to the Terms, for example by blocking access until they confirm the agreement. As this could deter visitors, it may be more suitable for restricted areas of a site such as a user account or member section.


